
В прошлой статье, где я разрабатывал Telegram-бот, возникала необходимость в кэшировании, чтобы избежать выполнения одинаковых запросов в течение дня к сервису ЦБ РФ. Если сохранять актуальные курсы валют, и, при следующем обращении пользователя, просто доставать их из кэша, то это значительно повлияет на быстродействие и стабильность приложения. Ведь каждый запрос по http выполняется определённое время, кроме этого, сторонний сервис может временно упасть, а это значит что и наш сервис в этом случае не сможет получить данные и показать их пользователю. Поскольку официальные курсы валют не меняются в течение дня, их смело можно кэшировать.
В конце я покажу как можно правильно доработать Telegram-бот, а пока что хочу разобрать несколько примеров того, как можно настроить кэширование данных в вашем приложении.
Как всегда, все исходники доступны на GitHub: https://github.com/AlexeyKutepov/spring-cache-example
Создание приложения на Spring Boot
По традиции, для генерации нового проекта на Spring Boot, я использую Spring Initializr. Моё тестовое приложение будет имитировать городскую библиотеку - в базе данных я буду хранить названия различных книг. Функционал будет предельно простой, а в качестве базы данных я возьму H2.
Зависимости
Начну с необходимых зависимостей. Вот так выглядит файл build.gradle в моём проекте:
plugins {
id 'java'
id 'org.springframework.boot' version '3.1.0'
id 'io.spring.dependency-management' version '1.1.0'
}
group = 'ru.akutepov'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '17'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.h2database:h2'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation group: 'org.junit.jupiter', name: 'junit-jupiter', version: '5.9.3'
}
tasks.named('test') {
systemProperty "file.encoding", "utf-8"
useJUnitPlatform()
}
Теперь немного расскажу о том что здесь есть. Так как всё затевается ради кеширования, то мне потребуется соответствующий стартер:
implementation 'org.springframework.boot:spring-boot-starter-cache'
Для комфортной работы с базой данных у меня есть второй стартер:
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
Ну и конечно же библиотека для работы с H2:
runtimeOnly 'com.h2database:h2'
База данных у меня будет in memory, соответственно доступна только в рантайме - для учебного проекта большего и не требуется.
Настройки
После того, как прописаны все зависимости, можно переходить к настройке подключения к базе данных. Для этого необходимо открыть файл resources/application.properties и прописать следующие параметры:
spring.datasource.url=jdbc:h2:mem:${random.uuid}
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.jpa.show-sql=true
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=update
Проперти вида spring.datasource.* отвечают за конфигурацию DataSource (подключение к базе данных). Spring Boot умеет подхватывать эти настройки автоматом, что очень удобно в данном случае - не нужно отдельно настраивать бины.
Оставшиеся проперти разберу чуть подробнее:
- spring.jpa.show-sql - включение/выключение логгирования sql-запросов. Я выставил true, так как это будет более наглядно показывать то, откуда берутся данные (из базы или кэша).
- spring.jpa.database-platform - настройка диалекта для работы с базой данных. Для H2 это org.hibernate.dialect.H2Dialect
- spring.jpa.hibernate.ddl-auto - настройка поведения Hibernate. Значение update означает что если в БД чего-то нет, или устарело, то Hibernate автоматом внесёт соответствующие изменения.
Инициализация базы данных
База данных будет существовать только в рантайме в оперативной памяти, а значит при запуске приложения необходимо создать в БД таблицу и заполнить её необходимыми данными. Для этого достаточно добавить в папку resources файл data.sql и при запуске приложения все скрипты будут автоматом выполнены. Вот содержимое данного файла:
CREATE TABLE book
(
id INT NOT NULL,
title VARCHAR(50) NOT NULL,
author VARCHAR(50) NOT NULL
);
INSERT INTO book (id, title, author) VALUES (1, 'Тихий дон', 'М. А. Шолохов');
INSERT INTO book (id, title, author) VALUES (2, 'Как закалялась сталь', 'Н. А. Островский');
INSERT INTO book (id, title, author) VALUES (3, 'Старуха Изергиль', 'М. Горький');
При запуске приложения будет создана таблица book, после чего в неё будут добавлены 3 записи.
Классы для работы с БД
Теперь я добавлю простую сущность для таблицы book, в которой планирую хранить список книг. Для этого создам пакет model и в нём класс Book:
package ru.akutepov.spring.cache.example.model;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
@Entity
@Table(name = "book")
public class Book {
@Id
private long id;
@Column(name = "title")
private String title;
@Column(name = "author")
private String author;
public Book() {
}
public Book(long id, String title, String author) {
this.id = id;
this.title = title;
this.author = author;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
Как видно из кода, класс Book имеет всего 3 переменные, которые соответствуют полям таблицы book в базе данных:
- id - идентификатор книги в базе данных, переменная помечена соответствующей аннотацией @Id. Чтобы максимально упростить проект, я даже не стал добавлять автогенерацию.
- title - название книги, маппится на поле title с помощью аннотации @Column(name = "title")
- author - автор книги, маппится на поле author с помощью аннотации @Column(name = "author")
Сам класс Book имеет аннотацию @Entity, которая говорит о том что это класс-сущность и аннотацию @Table, которая ассоциирует данный класс с таблицей book. У меня на сайте есть довольно старая статья на тему работы с базой данных, там эти вещи расписаны чуть более подробно. Я эту статью писал в 2016-м году, поэтому она несколько устарела, но всё равно многое там вполне актуально.
Для выполнения запросов к базе данных нужен интерфейс, который наследует поведение JpaRepository. Его я назову BookRepository и помещу в пакет repository:
package ru.akutepov.spring.cache.example.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import ru.akutepov.spring.cache.example.model.Book;
import java.util.Optional;
@Repository
public interface BookRepository extends JpaRepository<Book, Long> {
Optional<Book> findBookByTitleAndAuthor(String title, String author);
}
JpaRepository содержит базовые методы для выполнения запросов к базе данных, такие как поиск по идентификатору, сохранение и удаление записей. Интерфейс который наследует JpaRepository, так же имеет возможность расширить функционал за счёт новых методов, названия которых соответствует определённым правилам. Реализация данных методов генерируется автоматически.
В моём примере это метод findBookByTitleAndAuthor, который будет выполнять поиск книги по названию и автору. Я его просто прописываю в интерфейсе, без какой-либо реализации в наследуемых классах и он прекрасно будет работать.
Так же необходимо пометить интерфейс BookRepository аннотацией @Repository.
Класс конфигурации
Остался последний штрих и можно переходить к сервисному слою, в котором уже и будет реализовано кэширование данных. Необходимо в классе конфигурации прописать аннотацию @EnableCaching, чтобы кэширование было доступно в приложении:
package ru.akutepov.spring.cache.example.configuration;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Configuration;
@EnableCaching
@Configuration
public class AppConfiguration {
}
Сервисный слой
Логика кэширования будет располагаться в сервисном классе BookService, который располагается в пакете service, его я поэтапно буду разбирать чуть ниже. Кроме этого, тестировать функционал собираюсь с помощью unit-тестов, которые будут располагаться в классе BookServiceTest. Общая структура классов в моём приложении выглядит так:
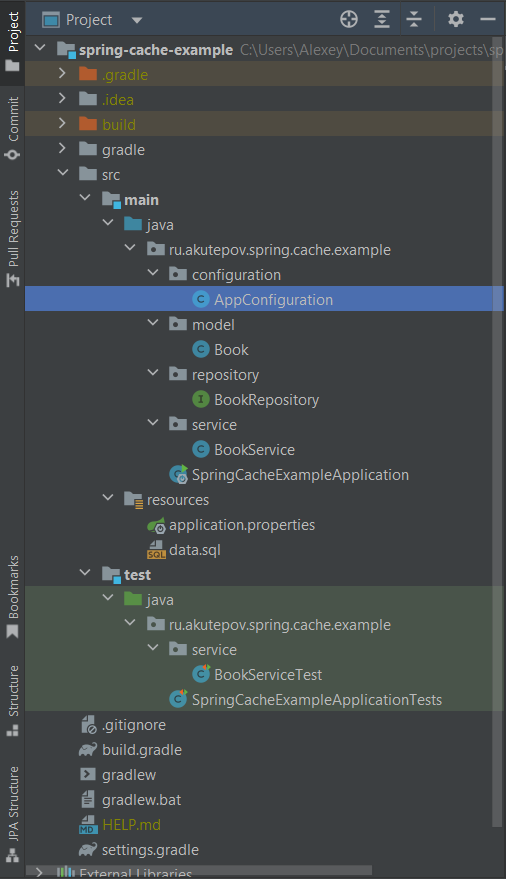
Обязательно убедитесь что ваш проект запускается и собирается, после чего можно двигаться дальше.
Работа с кэшем
В классе BookService я буду размещать различные методы, которые раскроют базовые возможности кэширования в приложении на Spring Boot. Пока что класс у меня выглядит следующим образом:
package ru.akutepov.spring.cache.example.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import ru.akutepov.spring.cache.example.repository.BookRepository;
@Service
public class BookService {
private static final Logger LOG = LoggerFactory.getLogger(BookService.class);
@Autowired
private BookRepository repository;
}
Я добавил сюда Logger для логирования работы методов и сразу заавтовайрил BookRepository для работы с базой данных.
Кэширование возвращаемого результата. @Cacheable
Начну я с простого - попробую закэшировать возвращаемый результат метода и посмотрю как это будет работать. Для этого добавлю в класс BookService такой метод:
@Cacheable("book")
public Book findBookById(long id) {
LOG.info("Calling getBookById...");
Optional<Book> bookOptional = repository.findById(id);
return bookOptional.orElse(null);
}
Данный метод пытается найти в базе данных книгу по её идентификатору, с помощью метода findById интерфейса BookRepository. Чтобы при каждом вызове findBookById не обращаться к базе данных, я закэшировал возвращаемый результат, добавив к методу аннотацию @Cacheable("book"). В значение value аннотации @Cacheable я передаю название кэша - "book". С помощью названия кэша можно группировать кэшируемые данные, например в кэше с названием "book" могут храниться данные о книгах, а какие-нибудь данные о сотрудниках библиотеки, можно разместить в кэше с другим названием - "employees".
В качестве ключа для значения, которое сохраняется в кэше, будет выступать переменная id. Когда вызывается первый раз метод findBookById с параметром id=3, то сначала выполняется поиск в кэше (но там пока ничего нет), далее идёт запрос к базе данных, найденное значение сохраняется в кэш с ключом 3 и возвращается пользователю. При втором вызове findBookById с параметром id=3 нужное значение будет найдено в кэше и обращения к базе данных не произойдёт.
Для того чтобы проверить вышесказанное, я написал простой юнит тест в классе BookServiceTest:
package ru.akutepov.spring.cache.example.service;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.mock.mockito.SpyBean;
import org.springframework.context.ApplicationContext;
import org.springframework.test.annotation.DirtiesContext;
import ru.akutepov.spring.cache.example.model.Book;
import ru.akutepov.spring.cache.example.repository.BookRepository;
import static org.junit.jupiter.api.Assertions.assertNotNull;
import static org.mockito.Mockito.times;
import static org.mockito.Mockito.verify;
@SpringBootTest
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_EACH_TEST_METHOD)
class BookServiceTest {
private static final Logger LOG = LoggerFactory.getLogger(BookServiceTest.class);
@Autowired
private ApplicationContext applicationContext;
@Autowired
private BookService service;
@SpyBean
@Autowired
private BookRepository repository;
@Test
void testFindBookById() {
final long bookId = 1L;
// первое обращение к сервису, получение данных из БД и кэширование
Book book = service.findBookById(bookId);
assertNotNull(book, "Book is not found");
LOG.info("Book: " + book.getTitle());
// второе обращение к сервису, получение данных из кэша
Book cachedBook = service.findBookById(bookId);
assertNotNull(cachedBook, "Book is not found");
LOG.info("Book: " + book.getTitle());
// данные из БД извлекаются только 1 раз при первом обращении
verify(repository, times(1)).findById(bookId);
}
}
Перед тем, как перейти непосредственно к unit-тесту, немного расскажу что здесь происходит:
- Аннотация @DirtiesContext отвечает за перезагрузку контекста, чтобы юнит-тесты друг другу не мешали и выполняли прогон на чистой базе и с чистым кэшем.
- ApplicationContext для тестов не нужен, но пригодится для демонстрации происходящего под капотом.
- Так же я использую Mockito и буду шпионить за бином BookRepository, чтобы понимать сколько обращений к базе данных было. Для этой цели и прописана аннотация @SpyBean.
А теперь можно переходить к unit-тесту testFindBookById. В нём я 2 раза вызываю сервисный метод findBookById, передавая один и тот же идентификатор, проверяю что данный метод не вернул null и проверяю количество обращений к базе данных, которое оцениваю по числу вызовов метода findById класса BookRepository:
verify(repository, times(1)).findById(bookId);
К базе данных должно быть только одно обращение, так как второй раз значение извлекается из кэша. Если запустить тест, то все проверки успешно отработают, кроме этого и по логам будет видно что запрос к базе был один, а возвращаемый результат заллогирован 2 раза:

Предлагаю пойти ещё дальше - включить debug и заглянуть под капот, чтобы увидеть где и как хранится кэш. Для этого потребуется ApplicationContex, чтобы вытащить из него бин cacheManager:
applicationContext.getBean("cacheManager");
Эту строчку можно добавить в конец любого метода с unit-тестом, а затем поставить на ней брейкпоинт, запустить тест под дебагом и выполнить Evaluate Expression, нажав правую кнопку мыши:
После чего появится возможность найти сохранённый кэш в структурах данных бина cacheManager:
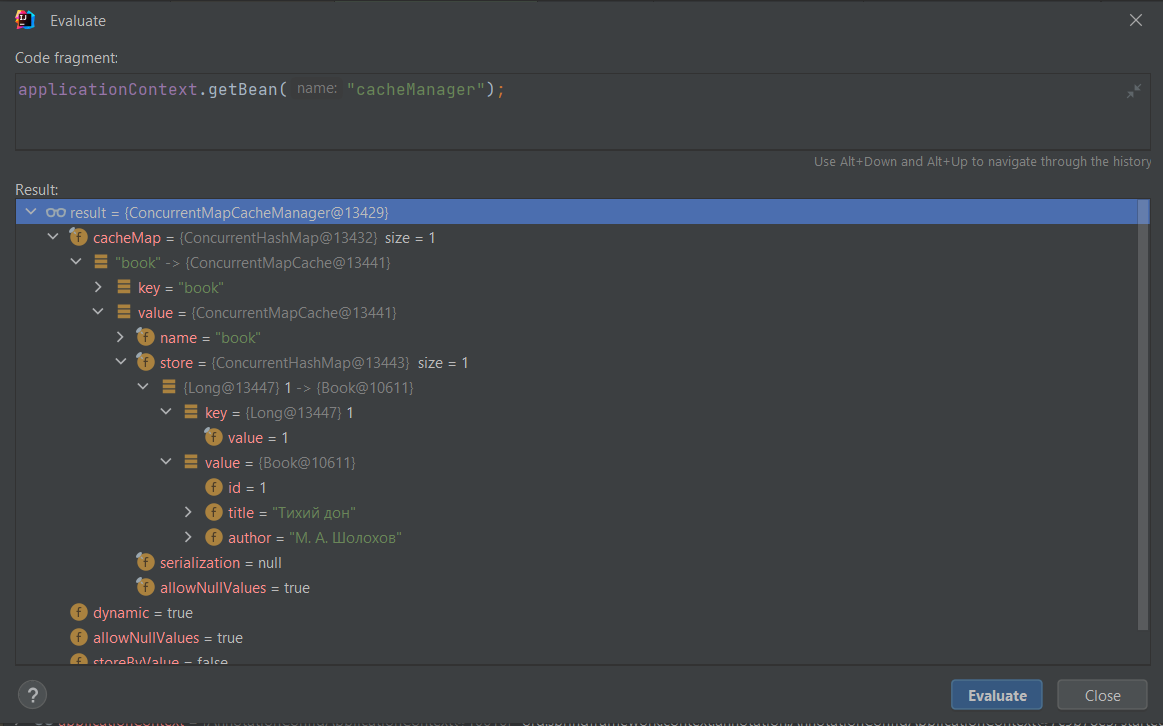
Как я и говорил, книга сохранилась в кэше с названием "book" под ключом, значение которого было передано в переменную id, то есть в данном случае это 1.
Условное кэширование
Я думаю вы уже обратили внимание, что метод findBookById может вернуть значение null, если книга не найдена по заданному идентификатору. Кэшировать null не только нет смысла, но и вредно в данном случае, так как книгу с таким идентификатором могут добавить в базу позже и если не обновить кэш, то метод findBookById продолжит возвращать null, не смотря на наличие книги в базе.
К счастью решить данную проблему довольно просто, аннотация @Cacheable имеет параметр unless, в котором можно задать условие попадания возвращаемого результата в кэш. Условие задаётся через специальные выражения, которые называются Spring Expression Language (SpEL). Я немного модифицировал код метода, чтобы пустой результат не попадал больше в кэш:
@Cacheable(value = "book", unless = "#result == null")
public Book findBookById(long id) {
LOG.info("Calling getBookById...");
Optional<Book> bookOptional = repository.findById(id);
return bookOptional.orElse(null);
}
После доработки можно написать unit-тест, который проверит что если возвращаемое значение null, то оно не попадёт в кэш:
@Test
void testFindBookByIdNullResult() {
final long bookId = 10L;
// первое обращение к сервису, в ответ возвращается null
Book book1 = service.findBookById(bookId);
assertNull(book1, "Book is found");
// второе обращение к сервису, в ответ возвращается null
Book book2 = service.findBookById(bookId);
assertNull(book2, "Book is found");
// так как значение null не кэшируется, то к БД будет 2 обращения
verify(repository, times(2)).findById(bookId);
}
Здесь так же 2 раза вызывается метод findBookById, но так как книги с индексом 10 в базе нет, то вернётся значение null. Поскольку такой результат в кэш не попадает, то при каждом вызове findBookById будет выполняться запрос в базу данных, что легко проверяется через verify.
Кэширование возвращаемого результата с выбором ключа
Часто в приложении могут присутствовать методы, которые на вход принимают несколько переменных или какой-нибудь сложный объект. Если результат работы таких методов необходимо закэшировать, то нужно как-то определиться и с тем, что будет выступать в роли ключа. Для этой цели аннотация @Cacheable содержит параметр key, в котором можно и можно задать ключ, используя Spring Expression Language (SpEL):
@Cacheable(value = "book", key = "#title", unless = "#result == null")
public Book findBookByTitleAndAuthor(String title, String author) {
LOG.info("Calling getBookById...");
Optional<Book> bookOptional = repository.findBookByTitleAndAuthor(title, author);
return bookOptional.orElse(null);
}
В моём примере поиск книги выполняется по названию и автору, однако, в качестве ключа для кэширования, выступает название книги key = "#title".
Кстати unit-тест очень схож с unit-тестом из предыдущего примера, все проверки остаются ровно такие же:
@Test
void testFindBookByTitleAndAuthor() {
// первое обращение к сервису, получение данных из БД и кэширование
Book book = service.findBookByTitleAndAuthor("Тихий дон", "М. А. Шолохов");
assertNotNull(book, "Book is not found");
LOG.info("Book: " + book.getTitle());
// второе обращение к сервису, получение данных из кэша
Book cachedBook = service.findBookByTitleAndAuthor("Тихий дон", "М. А. Шолохов");
assertNotNull(cachedBook, "Book is not found");
LOG.info("Book: " + book.getTitle());
// данные из БД извлекаются только 1 раз при первом обращении
verify(repository, times(1)).findBookByTitleAndAuthor("Тихий дон", "М. А. Шолохов");
}
Если запустить данный тест, то всё успешно отработает по аналогии с предыдущим тестом. Но я думаю что будет очень любопытно посмотреть как теперь хранится закэшированный объект. Для этого я повторю эксперимент с вытаскиванием бина cacheManager под дебагом:
applicationContext.getBean("cacheManager");
И вот итоговый результат:
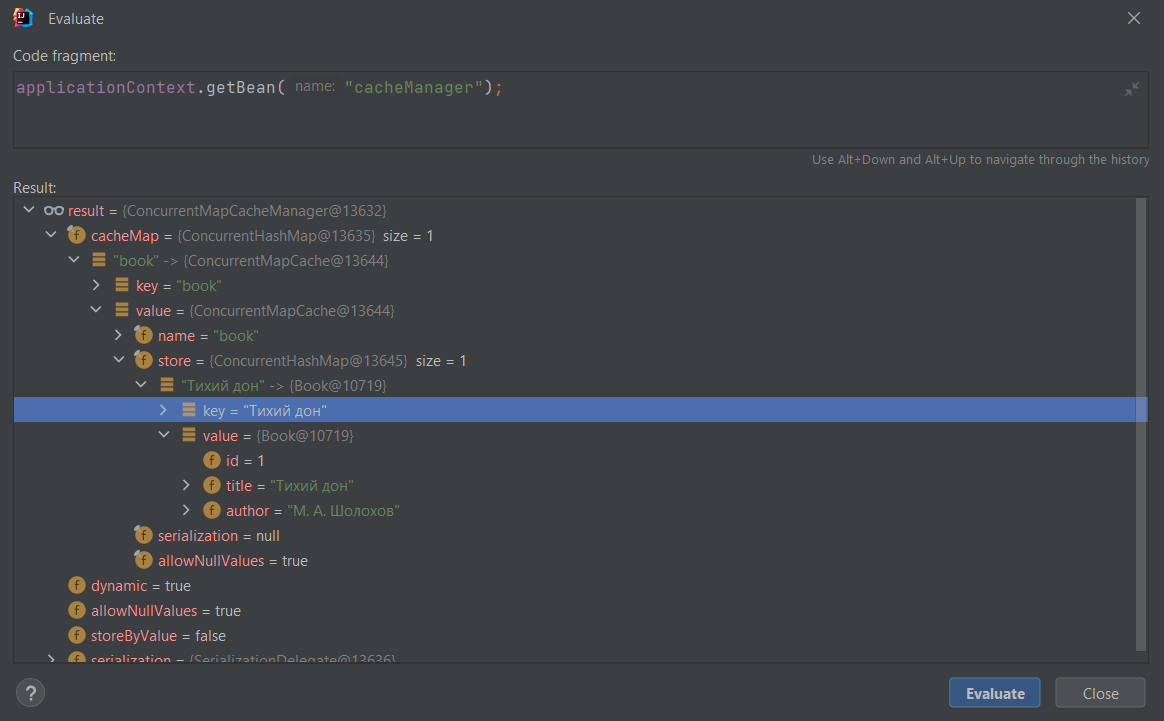
На скриншоте видно что в качестве ключа выступает уже название книги - "Тихий дон".
Принудительное добавление в кэш. @CachePut
Бывает и так, что нужно закэшировать данные принудительно. Например в базу данных добавляется новая запись и уже известно, что эту запись в дальнейшем придётся часто вытаскивать. Для таких случаев имеется аннотация @CachePut:
@CachePut(value = "book", key = "#book.id")
public Book saveBook(Book book) {
LOG.info("Calling saveBook...");
return repository.save(book);
}
Метод saveBook сохраняет в базу данных новую книгу и сразу же записывает её в кэш. В качестве ключа будет выступать идентификатор книги, что указано в параметрах аннотации с помощью SpEL выражения:
@CachePut(value = "book", key = "#book.id")
Предлагаю посмотреть как работает данный метод, написав ещё один unit-тест в классе BookServiceTest:
@Test
void testSaveBookAndPutCache() {
final long bookId = 4L;
Book book = new Book(bookId, "Капитанская дочка", "А.С. Пушкин");
// сохранение и кэширование
Book savedBook = service.saveBook(book);
// получение данных из кэша
Book foundedBook = service.findBookById(savedBook.getId());
assertNotNull(foundedBook, "Book is not found");
LOG.info("Book: " + foundedBook.getTitle());
// данные закэшированы при сохранении и при запросе из БД не извлекаются
verify(repository, never()).findById(bookId);
}
Вначале я инициализирую новый объект класса Book и сохраняю его с помощью метода saveBook в базу данных. Так как метод saveBook имеет аннотацию @CachePut, то это значит что книга будет принудительно помещена в кэш.
А далее происходит самое интересное - я вызываю метод поиска книги по идентификатору findById, в который передаю id только что сохранённой книги. Так как книга уже закэширована, метод findById её сразу вернёт не выполняя запросов к базе данных. Этот факт проверяется в самом конце с помощью verify:
verify(repository, never()).findById(bookId);
Если запустить unit-тест, то все проверки успешно отработают, а так же в логах можно будет увидеть что обращение к базе данных идёт только в момент сохранения книги:

Для большей наглядности я сделал в BookService ещё один метод сохранения книги в БД, но без принудительного кэширования:
public Book saveBookWithoutCachePut(Book book) {
LOG.info("Calling saveBookWithoutCachePut...");
return repository.save(book);
}
Теперь есть возможность написать для него похожий unit-тест и сравнить поведение метода saveBookWithoutCachePut с методом saveBook:
@Test
void testSaveBookWithoutPutCache() {
final long bookId = 5L;
Book book = new Book(bookId, "Война и мир", "Л.Н. Толстой");
// сохранение без кэширования
Book savedBook = service.saveBookWithoutCachePut(book);
// первое обращение к сервису, получение данных из БД и кэширование
Book foundedBook = service.findBookById(savedBook.getId());
assertNotNull(foundedBook, "Book is not found");
LOG.info("Book: " + foundedBook.getTitle());
// второе обращение к сервису, получение данных из кэша
foundedBook = service.findBookById(savedBook.getId());
assertNotNull(foundedBook, "Book is not found");
LOG.info("Book: " + foundedBook.getTitle());
// данные из БД извлекаются только 1 раз при первом обращении
verify(repository, times(1)).findById(bookId);
}
Так как метод saveBookWithoutCachePut принудительно не кэширует данные, то следует ожидать что при первом вызове метода findBookById будет попытка получить сохранённую книгу из базы данных. Поскольку метод findBookById имеет аннотацию @Cacheable, возвращаемый результат будет закэширован. Соответственно второй вызов findBookById вернёт книгу уже из кэша. С помощью verify я проверяю что было только одно обращение к базе данных не смотря на 2 вызова findBookById.
Если запустить тест, то в логах будет видно что обращение к базе данных было при сохранении книги и при первом вызове findBookById:
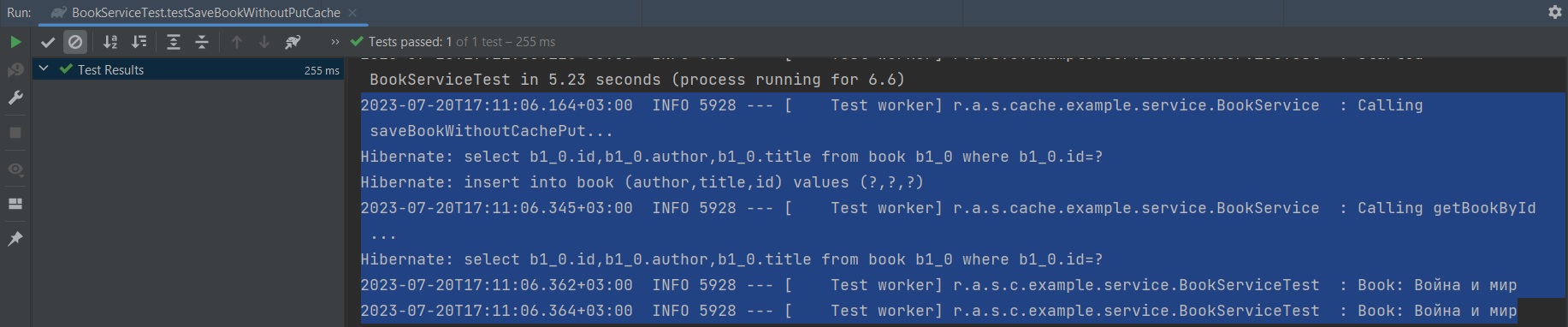
Удаление из кэша. @CacheEvict
Иногда данные перестают быть актуальными и их нужно принудительно удалить из кэша. Ещё этот процесс называют инвалидацией:
Инвалидация кеша - это процесс удаления всех кешированных объектов, связанных с изменениями в состоянии вашей модели.
Самый простой пример - удаление книги из базы данных. В этом случае нужно обязательно почистить кэш, чтобы пользователь не получил уже несуществующую книгу в ответе от сервиса:
@CacheEvict(value = "book", key = "#book.id")
public void deleteBook(Book book) {
LOG.info("Calling deleteBook...");
repository.delete(book);
}
В данном примере книга удаляется из базы данных и из кэша одновременно. Для этих целей есть аннотация @CacheEvict, которой проаннотирован метод deleteBook. Обратите внимание на то что явно указывается ключ, по которому хранится книга в кэше key = "#book.id". Это нужно для правильной работы метода, так как на вход передаётся вся сущность Book.
И по традиции простой unit-тест для проверки приведённого выше кода:
@Test
void testDeleteBookAndCacheEvict() {
final long bookId = 2L;
// получение данных из БД и кэширование
Book foundedBook = service.findBookById(bookId);
// удаление данных из БД и кэша
service.deleteBook(foundedBook);
foundedBook = service.findBookById(bookId);
assertNull(foundedBook, "Book is found");
}
Вначале я специально вызываю метод findBookById, чтобы данные о книге попали в кэш. После этого произвожу удаление книги из базы данных методом deleteBook, который так же удаляет данные о книге из кэша. И завершающим этапам снова вызываю findBookById, чтобы убедиться в том что в качестве ответа вернётся null, так как данные о книге должны везде отсутствовать. Вы можете запустить такой тест у себя и убедиться что всё работает правильно.
В качестве дополнительного эксперимента я решил сделать метод, который удаляет данные из базы, но при этом не чистит кэш:
public void deleteBookWithoutCacheEvict(Book book) {
LOG.info("Calling deleteBook...");
repository.delete(book);
}
И написал для метода deleteBookWithoutCacheEvict простой unit-тест чтобы продемонстрировать ситуацию, когда в кэше оказываются неактуальные данные:
@Test
void testDeleteBookWithoutCacheEvict() {
final long bookId = 3L;
// первый вызов findBookById, получение данных из БД и кэширование
Book foundedBook = service.findBookById(bookId);
// удаление данных из БД
service.deleteBookWithoutCacheEvict(foundedBook);
// второй вызов findBookById, получение закэшированных данных
foundedBook = service.findBookById(bookId);
assertNotNull(foundedBook, "Book is not found");
LOG.info("Book: " + foundedBook.getTitle());
// данные из БД извлекаются только 1 раз при первом обращении
verify(repository, times(1)).findById(bookId);
}
Вначале я так же вызываю метод findBookById, чтобы данные о книге попали в кэш. После этого произвожу удаление книги из базы данных, но уже методом deleteBookWithoutCacheEvict. Так как метод принудительно не очищает кэш, то повторный вызов findBookById вернёт данные о книге, но уже из кэша, хотя эти данные уже устарели. Этот факт легко подтвердит проверка:
assertNotNull(foundedBook, "Book is not found");
А verify тут на самом деле просто для наглядности, чтобы ещё раз убедиться что запрос данных из базы по идентификатору проводился только один раз. Второй раз книга была получена именно из кэша.
Доработка Telegram-бота
После того, как я рассказал об основных возможностях кэширования, можно доработать Telegram-бот из предыдущей статьи. Напомню, там был сервисный класс ExchangeRatesServiceImpl:
package ru.akutepov.exchangeratesbot.service.impl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.w3c.dom.Document;
import org.xml.sax.InputSource;
import ru.akutepov.exchangeratesbot.client.CbrClient;
import ru.akutepov.exchangeratesbot.exception.ServiceException;
import ru.akutepov.exchangeratesbot.service.ExchangeRatesService;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import java.io.StringReader;
@Service
public class ExchangeRatesServiceImpl implements ExchangeRatesService {
private static final String USD_XPATH = "/ValCurs//Valute[@ID='R01235']/Value";
private static final String EUR_XPATH = "/ValCurs//Valute[@ID='R01239']/Value";
@Autowired
private CbrClient client;
@Override
public String getUSDExchangeRate() throws ServiceException {
var xmlOptional = client.getCurrencyRatesXML();
String xml = xmlOptional.orElseThrow(
() -> new ServiceException("Не удалось получить XML")
);
return extractCurrencyValueFromXML(xml, USD_XPATH);
}
@Override
public String getEURExchangeRate() throws ServiceException {
var xmlOptional = client.getCurrencyRatesXML();
String xml = xmlOptional.orElseThrow(
() -> new ServiceException("Не удалось получить XML")
);
return extractCurrencyValueFromXML(xml, EUR_XPATH);
}
private static String extractCurrencyValueFromXML(String xml, String xpathExpression)
throws ServiceException {
var source = new InputSource(new StringReader(xml));
try {
var xpath = XPathFactory.newInstance().newXPath();
var document = (Document) xpath.evaluate("/", source, XPathConstants.NODE);
return xpath.evaluate(xpathExpression, document);
} catch (XPathExpressionException e) {
throw new ServiceException("Не удалось распарсить XML", e);
}
}
}
При вызове методов getUSDExchangeRate и getEURExchangeRate выполняется запрос к сервису ЦБ РФ для получения xml с текущими курсами валют. Но дело в том что официальный курс доллара и евро в течение дня не меняется, а значит есть смысл сохранять эти значения в кэше, чтобы избежать большого количества одних и тех же запросов в сторонний сервис.
Чтобы организовать кэширование данных в Telegram-боте, потребуется уже знакомый стартер:
implementation 'org.springframework.boot:spring-boot-starter-cache'
Так же не стоит забывать про аннотацию @EnableCaching - без неё ничего не заработает:
@EnableCaching
@Configuration
public class ExchangeRatesBotConfiguration {
Теперь можно прописать аннотации @Cacheable:
@Cacheable(value = "usd", unless = "#result == null or #result.isEmpty()")
@Override
public String getUSDExchangeRate() throws ServiceException {
var xmlOptional = client.getCurrencyRatesXML();
String xml = xmlOptional.orElseThrow(
() -> new ServiceException("Не удалось получить XML")
);
return extractCurrencyValueFromXML(xml, USD_XPATH);
}
@Cacheable(value = "eur", unless = "#result == null or #result.isEmpty()")
@Override
public String getEURExchangeRate() throws ServiceException {
var xmlOptional = client.getCurrencyRatesXML();
String xml = xmlOptional.orElseThrow(
() -> new ServiceException("Не удалось получить XML")
);
return extractCurrencyValueFromXML(xml, EUR_XPATH);
}
Тут есть один очень важный момент - у методов getUSDExchangeRate и getEURExchangeRate нет входных параметров, а значит в качестве значения ключа будет выступать название самого кэша. Если для этих двух методов использовать кэш с одинаковым названием, то получится конфликт - будет всегда возвращаться первый сохранённый в кэш курс валюты вне зависимости от того, какой метод вызывается. Именно поэтому в моём примере для этих методов я задал разные названия кэша.
Но и этого не достаточно, ведь ровно в полночь карета превратится в тыкву! А значит на следующий день Telegram-бот будет возвращать старые курсы доллара и евро, что никак не может меня устраивать. Необходима инвалидация кэша!
В класс ExchangeRatesServiceImpl я добавлю 2 новых метода, которые и будут очищать кэш:
@CacheEvict("usd")
@Override
public void clearUSDCache() {
LOG.info("Cache \"usd\" cleared!");
}
@CacheEvict("eur")
@Override
public void clearEURCache() {
LOG.info("Cache \"eur\" cleared!");
}
А так же потребуется шедуллер, который будет срабатывать в полночь и вызывать методы очистки кэша. Для работы шедуллера потребуется добавить в класс конфигурации аннотацию @EnableScheduling:
@Configuration
@EnableCaching
@EnableScheduling
public class ExchangeRatesBotConfiguration {
Класс шедуллера я разместил в пакете scheduler и назвал его InvalidationScheduler:
package ru.akutepov.exchangeratesbot.scheduler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import ru.akutepov.exchangeratesbot.service.ExchangeRatesService;
@Component
public class InvalidationScheduler {
@Autowired
private ExchangeRatesService service;
@Scheduled(cron = "* 0 0 * * ?")
public void invalidateCache() {
service.clearUSDCache();
service.clearEURCache();
}
}
Ровно в 00:00 будет срабатывать метод invalidateCache и вызывать методы clearUSDCache и clearEURCache каждую секунду в течение одной минуты. Это сделано для того, чтобы избежать кэширования неактуальных данных, если сервис ЦБ РФ не достаточно оперативно обновит курсы валют у себя. Но возможно чистить кэш в страховочном режиме нужно дольше, выяснить это можно только опытным путём и после этого уже более точно настраивать механизм инвалидации. А так механизм кэширования полностью готов!
В статье приведены базовые возможности кэширования данных без использования более продвинутых инструментов, таких как Ehcache. Но во многих случаях и этих возможностей может хватить, учитывая лёгкость их применения, как в примере с Telegram-ботом. Теперь и вы легко сможете настроить кэширование в своём приложении на Spring Boot.
На этом урок подходит к концу, благодарю за прочтение!
Как всегда исходники доступны на GitHub:
https://github.com/AlexeyKutepov/spring-cache-example
https://github.com/AlexeyKutepov/exchange-rates-bot
Так же приглашаю всех желающих подписаться на мой Telegram-канал, в котором я делюсь большим количеством полезной информации о разработке программного обеспечения (в том числе и своими новыми статьями): https://t.me/akutepov