
Если вы столкнулись с задачей распознавания текста, то в первую очередь необходимо обратить внимание на так называемые OCR-библиотеки. Вообще OCR (Optical Character Recognition) - это оптическое распознавание текста, то есть механический или электронный перевод изображений с текстом в текстовые данные. То есть формально, когда вы перепечатываете какой-либо текст, то реализуете один из механизмов OCR :)
Нас конечно же интересует чтобы программа сама смогла прочитать текст с картинки и предоставить текстовые данные в строковой переменной. Для этого существуют различные готовые библиотеки и одна из них - Tesseract. Сама библиотека Tesseract не имеет ничего общего с Python, по сути она содержит OCR-движок и программу командной строки. Поэтому для разработки на Pyhton нам потребуется специальный модуль pytesseract.
Подготовка
Перед тем как я начну использовать pytesseract, необходимо провести подготовительную работу. Так как у меня на компьютере Linux, мне нужно загрузить ряд пакетов чтобы начать разработку распознавалки текста. Для этого в командной строке необходимо выполнить:
$ sudo apt update
$ sudo apt install tesseract-ocr
$ sudo apt install libtesseract-dev
Этого достаточно чтобы распознать текст на английском языке, но моя цель - распознавание текстов на русском языке, поэтому потребуется поставить ещё один пакет:
$ sudo apt install tesseract-ocr-rus
У библиотеки Tesseract много языковых пакетов, поэтому если вам требуется возможность распознавать какой-либо другой язык, то выполняете комманду:
$ sudo apt install tesseract-ocr-[lang]
где вместо [lang] указываете название языка в сокращённом виде: https://tesseract-ocr.github.io/tessdoc/Data-Files-in-different-versions.html
А можно просто выполнить команду:
$ sudo apt install tesseract-ocr-all
и у вас будет поддержка всех языков, которые умеет распознавать Tesseract.
Я правда не разбирался как всё тоже самое провернуть в Windows, но если вам это интересно, напишите пожалуйста к статье комментарий или мне в личные сообщения - я дополню статью. А пока продолжаем работу в Linux :)
Создание проекта
Теперь нужно создать новый проект в IDE и настроить виртуальное окружение. Для распознавания текста необходимо поставить библиотеку pytesseract, как я уже писал выше, а так же потребуется pillow для загрузки изображений. Поэтому выполняем следующие команды:
pip3 install pytesseract
pip3 install pillow
Теперь у нас есть всё необходимое чтобы приступить к разработке приложения, которое будет распознавать текст.
Разработка
Само приложение будет максимально простым, ведь вся работа ложится на установленные библиотеки. Мне остаётся только написать несколько строчек чтобы всё заработало:
import pytesseract
from PIL import Image
# Загрузка изображения с текстом
image = Image.open("test.jpg")
# Распознавание текста
string = pytesseract.image_to_string(image, lang='rus')
# Вывод распознанного текста в консоль
print(string)
Вот и весь код! Единственный важный момент - нужно явно указывать язык при вызове метода image_to_string, так как библиотека не умеет самостоятельно определять язык, на котором написан текст.
Теперь попробуем распознать вот такую сложную по своей структуре страницу:

Запускаем программу и получаем следующий результат:
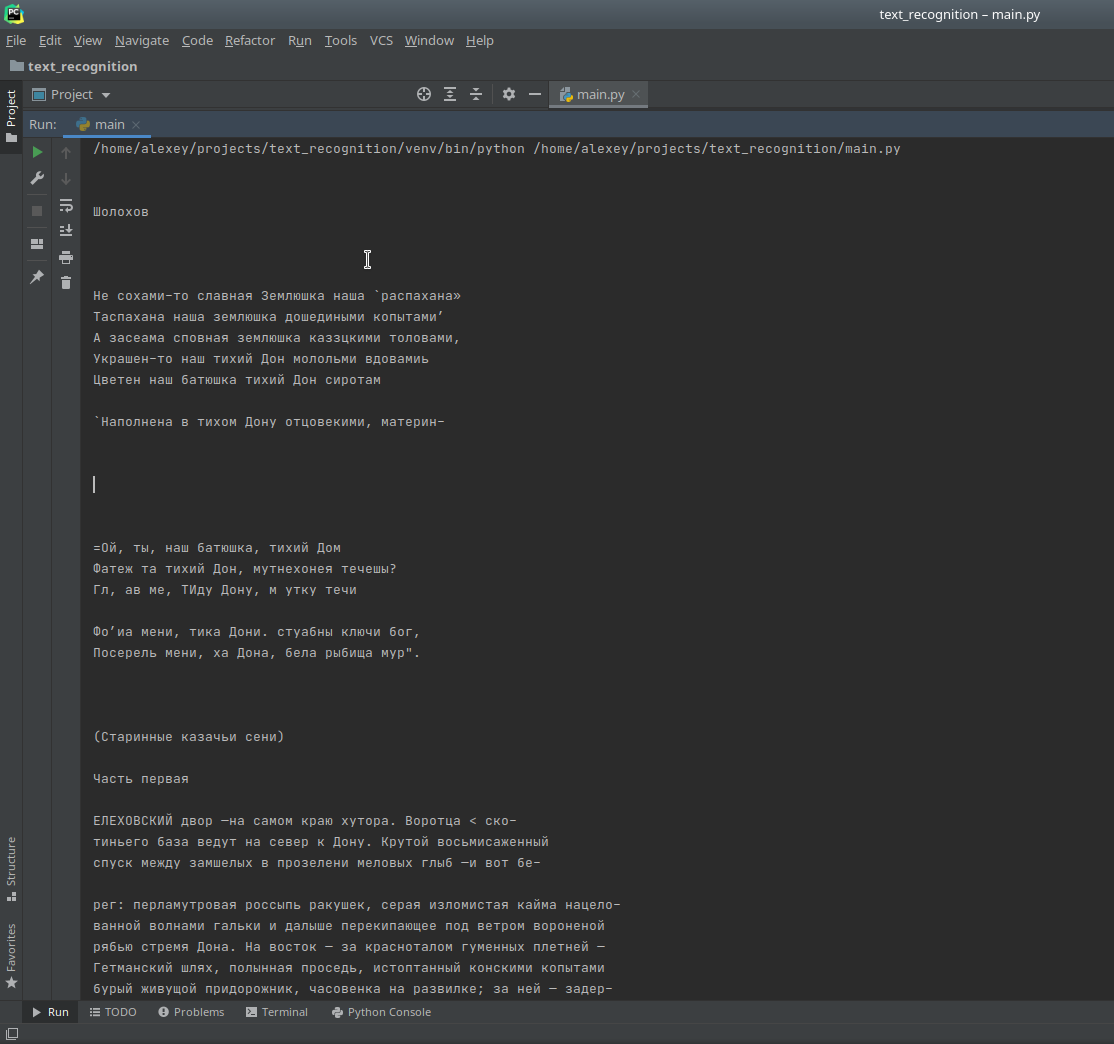
Не идеально конечно, но с учётом того что структура страницы сложная, качество изображения плохое и часть букв смазаны, то результат вполне себе хороший! Тут стоит вспомнить что даже старый добрый FineReader так же допускает ошибки при распознавании текста.
Современным разработчикам очень повезло - уже существуют множество готовых библиотек с очень серьёзными возможностями. Ещё лет 15-20 назад для решения подобной задачи пришлось бы потратить гораздо больше времени и скорее всего пришлось бы писать свой OCR-движок. Теперь достаточно написать несколько строчек кода чтобы получить на выходе достойный результат!